5.5. 5단계. 지식 검색 (Search) 및 LLM 요청/응답¶
저장된 지식을 검색하여 LLM에게 전달하고 최종 응답을 생성하는 과정
5.5.1. 필요성¶
RAG 시스템의 목적은 LLM이 검색된 정보를 중심으로 답변하도록 유도하는 것입니다.
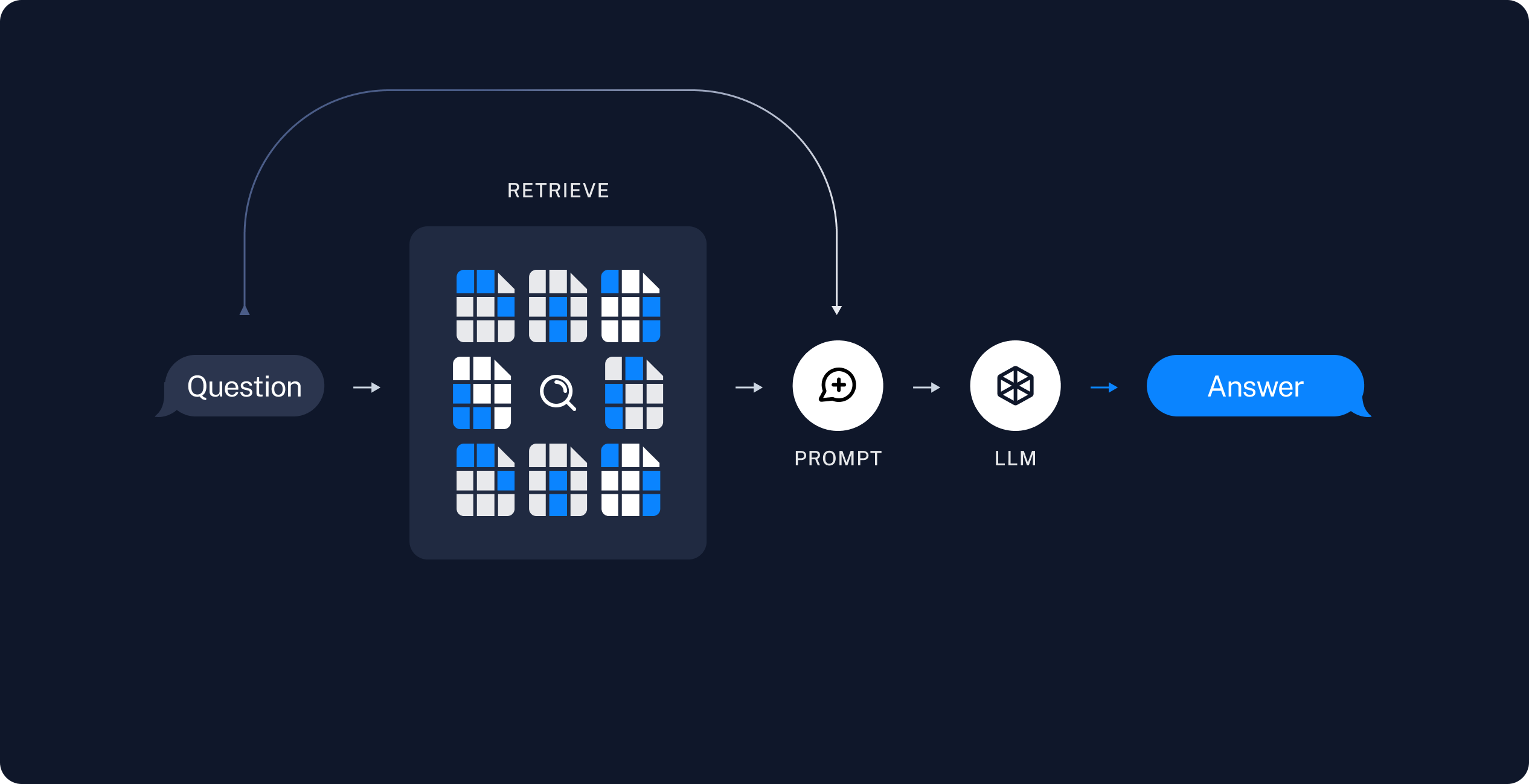
Question : 유저로부터 질문 받기
Retrieve : 질문에 대한 정보가 저장된 Vector Store에서 질문과 유사도가 높은 문서들을 k개 찾기
Prompt : 질문과 찾은 문서들을 프롬프트에 포함시켜 LLM에게 요청
각 단계를 순차적으로 수행하고 유저에게 답변을 전달합니다. 잘못된 문서가 검색되더라도 이를 검증하는 단계는 없습니다.
팁
질문과 유사 문서의 품질을 평가해서, 재질문 혹은 문서 재검색을 수행할 수도 있습니다.
RAG 검색 과정이 무조건 Question → Retrieve → Prompt 순서로 진행해야만 하는 것은 아닙니다. 다양한 프로세스가 있을 수 있습니다. 코드로 구현하기 나름입니다.
질문과 유사 문서의 품질을 평가해서, 재질문 혹은 문서 재검색을 수행할 수도 있습니다.
이러한 Flow를 파이썬 코드로 직접 구현할 수도 있겠구요.
LangGraph 라이브러리를 통해 Flow 구성을 좀 더 직관적으로 하실 수도 있습니다.
LangGraph가 필수인 것은 아닙니다. 하나의 선택지일 뿐입니다.
5.5.2. 파이썬 구현¶
5.5.2.1. VectorStore 클래스에 search 메서드 구현¶
먼저 질문과 유사한 문서를 찾아주는 search 메서드를 VectoreStore 클래스에 구현해봅시다.
인자로 질문과 찾고자 하는 유사 문서 개수를 받습니다.
유사 문서 개수는 디폴트로
4를 지정했구요. 랭체인에서도 디폴트로4입니다.
질문 문자열을 임베딩 벡터 배열로 변환합니다.
질문과 VectorStore 내에 저장된 모든 문서들과 코사인 유사도를 계산합니다.
유사도가 높은 순으로 정렬하여
k개를 반환합니다.
1import openai
2import numpy as np
3from sklearn.metrics.pairwise import cosine_similarity
4
5client = openai.Client()
6
7class VectorStore(list):
8 embedding_model = "text-embedding-3-small"
9
10 # ...
11
12 def search(self, question: str, k: int = 4) -> List[Document]:
13 """
14 질의 문자열을 받아서, 벡터 스토어에서 유사 문서를 최대 k개 반환
15 """
16
17 # 질문 문자열을 임베딩 벡터 배열로 변환
18 response = client.embeddings.create(
19 model=self.embedding_model,
20 input=question,
21 )
22 question_embedding = response.data[0].embedding # 1536 차원, float 배열
23
24 # VectorStore 내에 저장된 모든 벡터 데이터를 리스트로 추출
25 embedding_list = [row["embedding"] for row in self]
26
27 # 모든 문서와 코사인 유사도 계산
28 similarities = cosine_similarity([question_embedding], embedding_list)[0]
29 # 유사도가 높은 순으로 정렬하여 k 개 선택
30 top_indices = np.argsort(similarities)[::-1][:k]
31
32 # 상위 k 개 문서를 리스트로 반환
33 return [
34 self[idx]["document"].model_copy()
35 for idx in top_indices
36 ]
5.5.2.2. 1단계. Question¶
RAG를 수행할 질문을 먼저 정의합니다.
1question = "빽다방 카페인이 높은 음료와 가격은?"
5.5.2.3. 2단계. Retrieve¶
vector_store 에서 질문과 유사한 문서를 찾아서, 프롬프트에 바로 사용할 수 있도록 지식 문자열 변수로 저장합니다.
1search_doc_list: List[Document] = vector_store.search(question)
2pprint(search_doc_list)
3
4print("## 지식 ##")
5지식: str = str(search_doc_list)
6print(repr(지식))
아래와 같이 유사 문서를 찾아, 지식 문자열까지 잘 생성했습니다.
[Document(metadata={'source': '빽다방.txt'}, page_content='5. 빽사이즈 원조커피(ICED)\n - 빽다방의 BEST메뉴를 더 크게 즐겨보세요 :) [주의. 564mg 고카페인으로 카페인에 민감한 어린이, 임산부는 섭취에 주의바랍니다]\n - 가격: 4000원'),
Document(metadata={'source': '빽다방.txt'}, page_content='6. 빽사이즈 원조커피 제로슈거(ICED)\n - 빽다방의 BEST메뉴를 더 크게, 제로슈거로 즐겨보세요 :) [주의. 686mg 고카페인으로 카페인에 민감한 어린이, 임산부는 섭취에 주의바랍니다]\n - 가격: 4000원'),
Document(metadata={'source': '빽다방.txt'}, page_content='3. 사라다빵\n - 빽다방의 대표메뉴 :) 추억의 감자 사라다빵\n - 가격: 3900원'),
Document(metadata={'source': '빽다방.txt'}, page_content='2. 바닐라라떼(ICED)\n - 부드러운 우유와 달콤하고 은은한 바닐라가 조화를 이루는 음료\n - 가격: 4200원')]
## 지식 ##
"[Document(metadata={'source': '빽다방.txt'}, page_content='5. 빽사이즈 원조커피(ICED)\n - 빽다방의 BEST메뉴를 더 크게 즐겨보세요 :) [주의. 564mg 고카페인으로 카페인에 민감한 어린이, 임산부는 섭취에 주의바랍니다]\n - 가격: 4000원'), Document(metadata={'source': '빽다방.txt'}, page_content='6. 빽사이즈 원조커피 제로슈거(ICED)\n - 빽다방의 BEST메뉴를 더 크게, 제로슈거로 즐겨보세요 :) [주의. 686mg 고카페인으로 카페인에 민감한 어린이, 임산부는 섭취에 주의바랍니다]\n - 가격: 4000원'), Document(metadata={'source': '빽다방.txt'}, page_content='3. 사라다빵\n - 빽다방의 대표메뉴 :) 추억의 감자 사라다빵\n - 가격: 3900원'), Document(metadata={'source': '빽다방.txt'}, page_content='2. 바닐라라떼(ICED)\n - 부드러운 우유와 달콤하고 은은한 바닐라가 조화를 이루는 음료\n - 가격: 4200원')]"
5.5.2.4. 3단계. Prompt¶
대화 시작 시에 한 번에 모든 지식을 제공하기 에서는 모든 지식을 한 번에 프롬프트에 주입했었었구요.
이번에는 “빽다방 카페인이 높은 음료와 가격은?” 질문과 유사한 문서로만 잘 검색이 되었고 이를 프롬프트에 주입하겠습니다.
1res = client.chat.completions.create(
2 messages=[
3 {
4 "role": "system",
5 "content": f"넌 AI Assistant. 모르는 건 모른다고 대답.\n\n[[빽다방 메뉴 정보]]\n{지식}",
6 },
7 {
8 "role": "user",
9 "content": question,
10 },
11 ],
12 model="gpt-4o-mini",
13 temperature=0,
14)
15print()
16print("[AI]", res.choices[0].message.content)
17print_prices(res.usage.prompt_tokens, res.usage.completion_tokens)
RAG 답변을 받아보면, 검색된 지식에 기반해서 정확한 답변을 받았음을 확인하실 수 있습니다. 😉
[AI] 빽다방에서 카페인이 높은 음료는 다음과 같습니다:
1. 빽사이즈 원조커피(ICED) - 564mg 고카페인, 가격: 4000원
2. 빽사이즈 원조커피 제로슈거(ICED) - 686mg 고카페인, 가격: 4000원
이 두 음료가 카페인이 가장 높습니다.
input: tokens 293, krw 0.0659
output: tokens 93, krw 0.083700
5.5.3. 전체 코드¶
VectorStore.make 메서드 내에서 metadata를 추가로 저장하고, search 메서드에서도 기존 문서의 metadata를 추출해서 사용토록 개선했습니다.
경고
데이터 포맷이 변경되었으므로 기존 vector_store.pickle 파일을 삭제하시고 pickle 파일을 다시 생성해주세요.
재생성하지 않고 기존 pickle 데이터로 실행하시면 KeyError: 'metadata' 예외가 발생할 것입니다.
1# 의존 라이브러리 : pip install -U openai langchain scikit-learn numpy
2
3import pickle
4from pathlib import Path
5from pprint import pprint
6from typing import List
7
8import numpy as np
9import openai
10from environ import Env
11from langchain_community.utils.math import cosine_similarity
12from langchain_core.documents import Document
13
14
15env = Env()
16env.read_env() # .env 파일을 환경변수로서 로딩
17
18
19client = openai.Client()
20
21
22def print_prices(input_tokens: int, output_tokens: int) -> None:
23 input_price = (input_tokens * 0.150 / 1_000_000) * 1_500
24 output_price = (output_tokens * 0.600 / 1_000_000) * 1_500
25 print("input: tokens {}, krw {:.4f}".format(input_tokens, input_price))
26 print("output: tokens {}, krw {:4f}".format(output_tokens, output_price))
27
28
29def load() -> List[Document]:
30 file_path = "빽다방.txt"
31 지식: str = open(file_path, "rt", encoding="utf-8").read()
32 docs = [
33 Document(
34 # 의미있는 메타데이터가 있다면, 맘껏 더 담으시면 됩니다.
35 metadata={"source": file_path},
36 page_content=지식,
37 )
38 ]
39 return docs
40
41
42def split(src_doc_list: List[Document]) -> List[Document]:
43 new_doc_list = []
44 for doc in src_doc_list:
45 for new_page_content in doc.page_content.split("\n\n"):
46 new_doc_list.append(
47 Document(
48 metadata=doc.metadata.copy(),
49 page_content=new_page_content,
50 )
51 )
52 return new_doc_list
53
54
55class VectorStore(list):
56 embedding_model = "text-embedding-3-small"
57
58 @classmethod
59 def make(cls, doc_list: List[Document]) -> "VectorStore":
60 vector_store = cls()
61
62 for doc in doc_list:
63 response = client.embeddings.create(
64 model=cls.embedding_model,
65 input=doc.page_content,
66 )
67 vector_store.append(
68 {
69 "document": doc.model_copy(),
70 "embedding": response.data[0].embedding,
71 }
72 )
73
74 return vector_store
75
76 def save(self, vector_store_path: Path) -> None:
77 """
78 벡터 스토어 문서/임베딩 데이터를 지정 경로에 파일로 저장
79 """
80 with vector_store_path.open("wb") as f:
81 # 리스트(self)를 pickle 포맷으로 파일(f)에 저장
82 pickle.dump(self, f)
83
84 @classmethod
85 def load(cls, vector_store_path: Path) -> "VectorStore":
86 """
87 지정 경로의 파일을 읽어서 벡터 스토어 문서/임베딩 데이터 복원
88 """
89 with vector_store_path.open("rb") as f:
90 # pickle 포맷으로 파일(f)에서 리스트(VectorStore)를 로딩
91 return pickle.load(f)
92
93 def search(self, question: str, k: int = 4) -> List[Document]:
94 """
95 질의 문자열을 받아서, 벡터 스토어에서 유사 문서를 최대 k개 반환
96 """
97
98 # 질문 문자열을 임베딩 벡터 배열로 변환
99 response = client.embeddings.create(
100 model=self.embedding_model,
101 input=question,
102 )
103 question_embedding = response.data[0].embedding # 1536 차원, float 배열
104
105 # VectorStore 내에 저장된 모든 문자열을 리스트로 추출
106 embedding_list = [row["embedding"] for row in self]
107
108 # 모든 데이터와 코사인 유사도 계산
109 similarities = cosine_similarity([question_embedding], embedding_list)[0]
110 # 유사도가 높은 순으로 정렬하여 k 개 선택
111 top_indices = np.argsort(similarities)[::-1][:k]
112
113 # 상위 k 개 문서를 리스트로 반환
114 return [
115 self[idx]["document"].model_copy()
116 for idx in top_indices
117 ]
위에서 생성된 VectorStore 클래스를 다음과 같이 활용할 수 있습니다.
1def main():
2 vector_store_path = Path("vector_store.pickle")
3
4 # 첫번째 실행에서는 vector_store.pickle 파일이 없으므로 load, split, make, save 순서로 데이터를 생성하고 저장합니다.
5 if not vector_store_path.is_file():
6 doc_list = load()
7 print(f"loaded {len(doc_list)} documents")
8 doc_list = split(doc_list)
9 print(f"split into {len(doc_list)} documents")
10 vector_store = VectorStore.make(doc_list)
11 vector_store.save(vector_store_path)
12 print(f"created {len(vector_store)} items in vector store")
13 # 이후 실행에서는 vector_store.pickle 파일이 있으므로 load 순서로 데이터를 로딩합니다.
14 else:
15 vector_store = VectorStore.load(vector_store_path)
16 print(f"loaded {len(vector_store)} items in vector store")
17
18 question = "빽다방 카페인이 높은 음료와 가격은?"
19
20 search_doc_list: List[Document] = vector_store.search(question)
21 pprint(search_doc_list)
22
23 print("## 지식 ##")
24 지식: str = str(search_doc_list)
25 print(repr(지식))
26
27 res = client.chat.completions.create(
28 messages=[
29 {
30 "role": "system",
31 "content": f"넌 AI Assistant. 모르는 건 모른다고 대답.\n\n[[빽다방 메뉴 정보]]\n{지식}",
32 },
33 {
34 "role": "user",
35 "content": question,
36 },
37 ],
38 model="gpt-4o-mini",
39 temperature=0,
40 )
41 print_prices(res.usage.prompt_tokens, res.usage.completion_tokens)
42 ai_message = res.choices[0].message.content
43
44 print("[AI]", ai_message)
45
46
47if __name__ == "__main__":
48 main()
실행결과는 아래와 같습니다.
loaded 1 documents
split into 10 documents
created 10 items in vector store
[Document(metadata={'source': '빽다방.txt'}, page_content='5. 빽사이즈 원조커피(ICED)\n - 빽다방의 BEST메뉴를 더 크게 즐겨보세요 :) [주의. 564mg 고카페인으로 카페인에 민감한 어린이, 임산부는 섭취에 주의바랍니다]\n - 가격: 4000원'),
Document(metadata={'source': '빽다방.txt'}, page_content='6. 빽사이즈 원조커피 제로슈거(ICED)\n - 빽다방의 BEST메뉴를 더 크게, 제로슈거로 즐겨보세요 :) [주의. 686mg 고카페인으로 카페인에 민감한 어린이, 임산부는 섭취에 주의바랍니다]\n - 가격: 4000원'),
Document(metadata={'source': '빽다방.txt'}, page_content='3. 사라다빵\n - 빽다방의 대표메뉴 :) 추억의 감자 사라다빵\n - 가격: 3900원'),
Document(metadata={'source': '빽다방.txt'}, page_content='2. 바닐라라떼(ICED)\n - 부드러운 우유와 달콤하고 은은한 바닐라가 조화를 이루는 음료\n - 가격: 4200원')]
## 지식 ##
"[Document(metadata={'source': '빽다방.txt'}, page_content='5. 빽사이즈 원조커피(ICED)\n - 빽다방의 BEST메뉴를 더 크게 즐겨보세요 :) [주의. 564mg 고카페인으로 카페인에 민감한 어린이, 임산부는 섭취에 주의바랍니다]\n - 가격: 4000원'), Document(metadata={'source': '빽다방.txt'}, page_content='6. 빽사이즈 원조커피 제로슈거(ICED)\n - 빽다방의 BEST메뉴를 더 크게, 제로슈거로 즐겨보세요 :) [주의. 686mg 고카페인으로 카페인에 민감한 어린이, 임산부는 섭취에 주의바랍니다]\n - 가격: 4000원'), Document(metadata={'source': '빽다방.txt'}, page_content='3. 사라다빵\n - 빽다방의 대표메뉴 :) 추억의 감자 사라다빵\n - 가격: 3900원'), Document(metadata={'source': '빽다방.txt'}, page_content='2. 바닐라라떼(ICED)\n - 부드러운 우유와 달콤하고 은은한 바닐라가 조화를 이루는 음료\n - 가격: 4200원')]"
input: tokens 360, krw 0.0810
output: tokens 115, krw 0.103500
[AI] 빽다방에서 카페인이 높은 음료는 다음과 같습니다:
1. **빽사이즈 원조커피(ICED)**
- 카페인: 564mg
- 가격: 4000원
2. **빽사이즈 원조커피 제로슈거(ICED)**
- 카페인: 686mg
- 가격: 4000원
이 두 음료는 카페인 함량이 높으니 섭취에 주의하시기 바랍니다.
5.5.4. 마무리¶
축하드립니다. RAG 과정을 바닥부터 구현해보셨습니다. 🎉
RAG에 대한 이해가 만들어지셨으니, 이제 전형적인 RAG (랭체인 버전) 를 살펴보시면 각각의 동작이 보이고, 더 쉽게 구현할 수 있을 것입니다.