4. 빽다방 모델 및 최대 토큰수 유효성 검사¶
전형적인 RAG에서 빽다방 메뉴 문서를 파이썬 리스트에 저장했던 임베딩을
pgvector 확장과 장고 모델을 통해 Postgres 데이터베이스에 저장해보겠습니다.
변경 파일을 한 번에 덮어쓰기 하실려면, pyhub-git-commit-apply 유틸리티 설치하신 후에, rag-02 폴더 상위 경로에서 아래 명령어 실행
uv run pyhub-git-commit-apply https://github.com/pyhub-kr/django-llm-chat-proj/commit/470021caf41280d9fc98037835762efb4c1870d8
4.1. 커스텀 settings¶
RAG 관련 설정들을 일원화하여 관리하기 위해 다음과 같이 커스텀 settings를 정의하고, 환경변수 값을 파싱하여 각 설정값들을 초기화합니다.
OpenAI API는 서비스 전반적으로 사용되기에 전역 설정값을 정의하고, RAG에서는 다른 API Key 혹은 다른 서비스의 API을 호출할 수 있기에 설정값들은 별도로 정의합니다.
RAG_* 설정값을 사용하는 각종 RAG 모듈에서도 RAG 모듈에 따라 다른 API Key 혹은 다른 서비스를 사용할 수도 있기에
RAG_* 설정값을 디폴트 값으로 사용하겠습니다.
mysite/settings.py¶# 디폴트 값으로 사용할 OpenAI API key와 BASE_URL
OPENAI_API_KEY = env.str("OPENAI_API_KEY", default=None)
OPENAI_BASE_URL = env.str("OPENAI_BASE_URL", default=None)
# RAG에서 사용할 OpenAI API key와 BASE_URL
RAG_OPENAI_API_KEY = env.str("RAG_OPENAI_API_KEY", default=OPENAI_API_KEY)
RAG_OPENAI_BASE_URL = env.str("RAG_OPENAI_BASE_URL", default=OPENAI_BASE_URL)
# RAG에서 사용할 임베딩 모델
RAG_EMBEDDING_MODEL = env.str("RAG_EMBEDDING_MODEL", default="text-embedding-3-small")
# RAG에서 사용할 임베딩 모델의 차원수
RAG_EMBEDDING_DIMENSIONS = env.int("RAG_EMBEDDING_DIMENSIONS", default=1536)
4.2. 문서 모델 정의¶
PaikdabangMenuDocument 모델을 새롭게 정의하고, 랭체인의 Document 클래스 구성을 따라
page_content 필드와 metadata 필드를 추가하고,
임베딩 데이터를 저장할 embedding 필드를 VectorField 타입으로 정의합니다.
최대 2000 차원까지 저장할 수 있습니다.
각 모델에서 사용할 api key, base url, 임베딩 모델, 차원수 설정값은 클래스 변수로 두어,
각 설정값을 모델 클래스 내에서 일관되게 참조할 수 있도록 합니다. 설정값 변경 시 클래스 변수 한 곳만 수정하면 됩니다.
아래 모델 구성은 다른 모델에도 동일하게 적용할 수 있구요.
단, 인덱스 name 속성값은 데이터베이스에서 유일한 값으로 지정해주어야 합니다.
chat/models.py¶ 1from django.conf import settings
2from pgvector.django import VectorField, HnswIndex
3
4class PaikdabangMenuDocument(models.Model):
5 openai_api_key = settings.RAG_OPENAI_API_KEY
6 openai_base_url = settings.RAG_OPENAI_BASE_URL
7 embedding_model = settings.RAG_EMBEDDING_MODEL
8 embedding_dimensions = settings.RAG_EMBEDDING_DIMENSIONS
9
10 page_content = models.TextField()
11 metadata = models.JSONField(default=dict)
12 embedding = VectorField(dimensions=embedding_dimensions, editable=False)
13 created_at = models.DateTimeField(auto_now_add=True)
14 updated_at = models.DateTimeField(auto_now=True)
15
16 class Meta:
17 indexes = [
18 HnswIndex(
19 name="paikdabang_menu_doc_idx", # 데이터베이스 내에서 유일한 이름이어야 합니다.
20 fields=["embedding"],
21 m=16,
22 ef_construction=64,
23 opclasses=["vector_cosine_ops"],
24 ),
25 ]
방금 새로운 모델을 정의했으니, 모델 변경사항을 데이터베이스에 적용합니다.
# 모델 변경내역 대로 마이그레이션 파일을 생성합니다.
uv run python manage.py makemigrations chat
# 지정 마이그레이션 파일에 대한 SQL 수행 내역을 확인합니다.
# 현재 활성화된 데이터베이스 엔진에 따라 수행되는 SQL이 다릅니다.
uv run python manage.py sqlmigrate chat 0002
# 마이그레이션 파일을 데이터베이스에 적용합니다.
uv run python manage.py migrate chat
인덱스 name 속성값이 중복될 경우
인덱스 name 속성값이 중복될 경우, makemigrations 명령을 실행할 때 SystemCheckError 오류가 발생합니다.
반드시 인덱스 이름은 데이터베이스 내에서 유일한 값으로 지정되어야 합니다.
?: (models.E030) index name 'paikdabang_menu_doc_idx' is not unique among models:
chat.PaikdabangMenuDocument, chat.StarbucksMenuDocument
VectorField 타입은 최대 2000 차원까지 지원합니다.
OpenAI의 임베딩 모델은 차원수가 다릅니다. text-embedding-3-small 모델은 1536 차원을,
text-embedding-3-large 모델은 3072 차원을 사용합니다.
VectorField는 최대 2000 차원까지만 지원하므로, 3072 차원의 text-embedding-3-large 모델을 사용할 때는
HalfVectorField를 사용해야 합니다.
4.3. 최대 토큰 수 유효성 검사¶
OpenAI 임베딩 공식문서에 따르면 OpenAI 임베딩 API는 총 3개의 모델을 지원하며, 각 모델의 최대 토큰 수는 다음과 같습니다.
text-embedding-3-small:8191text-embedding-3-large:8191text-embedding-ada-002:8191
최대 토큰 수를 초과한 임베딩 API 요청은 다음과 같은 BadRequestError 예외가 발생합니다.
BadRequestError 예외 메시지
BadRequestError: Error code: 400 - {‘error’: {‘message’: “This model’s maximum context length is 8192 tokens, however you requested 8193 tokens (8193 in your prompt; 0 for the completion). Please reduce your prompt; or completion length.”, ‘type’: ‘invalid_request_error’, ‘param’: None, ‘code’: None}}
page_content 필드에 저장한 문자열을 줄이지 않으면 임베딩을 진행할 수 없게 됩니다.
page_content 필드에 값을 저장하기 전에 최대 토큰 수를 초과하지 않는 지 반드시 검사를 수행해야 할 것입니다.
백엔드 단에서의 유효성 검사는 필수입니다.
유효성 검사를 수행하고 유효성 검사 통과 여부를 판단하는 것은 장고의 기본 기능입니다. 직접 유효성 검사 루틴을 구성할 필요가 전혀 없습니다. 장고에서는 모델 필드나 폼 필드에 유효성 검사 함수만 지정하면, 유효성 검사 수행 시점에 유효성 검사 통과 여부를 판단하고 에러 메세지도 자동으로 생성해주며, 에러 메시지에 대한 HTML 태그도 자동으로 생성해줍니다.
models.CharField 모델 필드는 max_length 인자가 필수이며 이를 통해 최대 글자수를 검증하는 유효성 검사기가 자동으로 추가됩니다.
models.TextField 모델 필드는 기본적으로 문자열 길이를 검증하지 않지만, validators 인자를 통해 원하는 유효성 검사기를 추가할 수 있습니다.
장고 기본에서는 최대 글자수를 검증하는 MaxLengthValidator를 제공하지만, 토큰 수를 검증하는 유효성 검사기는 없습니다.
그래서 입력 값의 최대 토큰 수를 검증하는 MaxTokenValidator를 만들겠구요.
인자로 임베딩 모델명을 받아 최대 토큰 수를 인지하도록 합니다.
chat/models.py¶ 1from .validators import MaxTokenValidator # 곧 구현할 유효성 검사기
2
3class PaikdabangMenuDocument(LifecycleModelMixin, models.Model):
4 openai_api_key = settings.RAG_OPENAI_API_KEY
5 embedding_model = settings.RAG_EMBEDDING_MODEL
6 embedding_dimensions = settings.RAG_EMBEDDING_DIMENSIONS
7
8 page_content = models.TextField(
9 validators=[MaxTokenValidator(embedding_model)],
10 )
OpenAI Cookbook의 How to count tokens with Tiktoken 문서를
참고하여 MaxTokenValidator를 아래와 같이 구현했습니다.
임베딩 모델마다 최대 토큰 수가 고정되어있으므로, 인자로 임베딩 모델명만 받으면 내부적으로 최대 토큰 수를 인지할 수 있습니다.
지정 임베딩 모델의 최대 토큰 수 값을 찾지 못해
KeyError예외가 발생하면, 이를 유효성 검사 에러로 발생시킬려면ValidationError예외 발생 시점을 Validator 생성자가 아니라 유효성 검사 시점으로 미루어야 합니다.BaseValidator에서는limit_value인자로 인자없는 함수를 지원하며, 유효성 검사 시점에 호출하여 반환값을 사용합니다.limit_value인자로get_limit_value함수를 전달하고 함수 내부에서KeyError예외가 발생하면ValidationError예외를 발생시키도록 했습니다.
chat/validators.py¶ 1import tiktoken
2from django.core.exceptions import ValidationError
3from django.core.validators import BaseValidator
4from django.utils.deconstruct import deconstructible
5from django.utils.translation import ngettext_lazy
6
7@deconstructible
8class MaxTokenValidator(BaseValidator):
9 message = ngettext_lazy(
10 "토큰 수는 최대 %(limit_value)d개여야 합니다 (현재 %(show_value)d개).",
11 "토큰 수는 최대 %(limit_value)d개여야 합니다 (현재 %(show_value)d개).",
12 "limit_value",
13 )
14 code = "max_tokens"
15
16 # https://platform.openai.com/docs/guides/embeddings
17 max_input_tokens = {
18 "text-embedding-3-small": 8191,
19 "text-embedding-3-large": 8191,
20 "text-embedding-ada-002": 8191,
21 }
22
23 def __init__(
24 self,
25 model_name="text-embedding-3-small",
26 message=None,
27 ):
28 # limit_value 인자로 함수를 전달하면 유효성 검사를 수행하는 시점에 함수가 호출되어
29 # 반환된 값을 limit_value 값으로 사용합니다.
30 def get_limit_value():
31 try:
32 return self.max_input_tokens[model_name]
33 except KeyError:
34 raise ValidationError("Not found max input tokens for '%s'" % model_name)
35
36 self.model_name = model_name
37 super().__init__(limit_value=get_limit_value, message=message)
38
39 def compare(self, a, b) -> bool:
40 return a > b
41
42 def clean(self, x: str) -> int:
43 """주어진 텍스트의 토큰 수를 계산합니다.
44
45 Args:
46 x: 토큰 수를 계산할 텍스트 문자열
47
48 Returns:
49 int: 계산된 토큰 수
50
51 Raises:
52 ValidationError: 유효하지 않은 임베딩 모델명이 지정된 경우
53
54 References:
55 https://cookbook.openai.com/examples/how_to_count_tokens_with_tiktoken
56 """
57 try:
58 encoding: tiktoken.Encoding = tiktoken.encoding_for_model(self.model_name)
59 except KeyError:
60 raise ValidationError("Not found encoding for '%s'" % self.model_name)
61 num_tokens = len(encoding.encode(x or ""))
62 return num_tokens
MaxTokenValidator 유효성 검사기를 통해 직접 사용해보겠습니다. text-embedding-3-small 모델의 최대 토큰 수는 8191개이므로,
8191개 이하의 토큰 수를 가진 문자열은 유효성 검사를 통과하고, 8192개 이상의 토큰 수를 가진 문자열은 유효성 검사를 실패합니다.
>>> import tiktoken
>>> from chat.validators import MaxTokenValidator
>>> validator = MaxTokenValidator("text-embedding-3-small")
>>> encoding = tiktoken.encoding_for_model("text-embedding-3-small")
>>> x1 = "hello" * 8191
>>> len(encoding.encode(x1))
8191
>>> validator(x1) # 유효성 검사 통과 ✅
>>> x2 = "hello" * 8192
>>> len(encoding.encode(x2))
8192
>>> validator(x2) # 유효성 검사 실패 ❌
ValidationError: ['토큰 수는 최대 8191개여야 합니다 (현재 8192개).']
장고에서 유효성 검사 통과 여부는 ValidationError 예외 발생 여부로만 판단합니다.
장고에서는 유효성 검사 시에 각 유효성 검사 함수를 호출하여 ValidationError 예외 발생 여부로만 유효성 검사 통과 여부를 판단합니다.
함수 반환값도 사용되지 않기에 값을 반환하셔도 전혀 사용되지 않습니다.
import re
def validate_has_korean(value: str) -> None:
if not re.search("[가-힣]", value):
raise ValidationError("한글이 포함되지 않은 문자열은 스팸으로 판단되어 허용되지 않습니다.")
return value # 값을 반환되어도 사용되어지지 않고, 무시됩니다.
반면 장고 폼에서의 clean_필드명, clean 메서드는 유효성 검사를 비롯하여 값 변환 기능도 제공하기에,
clean 메서드의 반환값은 변환된 값이 됩니다.
4.4. MaxTokenValidator 활용 예¶
MaxTokenValidator 유효성 검사기가 적용된 page_content 필드에 8192개 토큰을 가지는 문자열을 저장하면,
유효성 검사를 통과하지 못하고 ValidationError 예외가 발생합니다.
>>> from chat.models import PaikdabangMenuDocument
>>> doc = PaikdabangMenuDocument(page_content=x2)
>>> doc.full_clean()
ValidationError: {'page_content': ['토큰 수는 최대 8191개여야 합니다 (현재 8192개).']}
PaikdabangMenuDocument 모델 기반으로 ModelForm을 구성하면,
폼 유효성 검사 시점(.is_valid() 메서드 호출)에 모델의 .full_clean() 메서드를 호출하여 유효성 검사를 수행합니다.
chat/forms.py¶1from django import forms
2from .models import PaikdabangMenuDocument
3
4class PaikdabangMenuDocumentForm(forms.ModelForm):
5 class Meta:
6 model = PaikdabangMenuDocument
7 fields = ["page_content", "metadata"]
8192개 토큰을 가지는 문자열을 지정하고 .is_valid() 메서드를 호출하여 유효성 검사를 수행하면
유효성 검사에 실패했기에 False을 반환하구요.
.errors 속성은 유효성 검사 실패 시 발생한 에러 메세지를 포함한 딕셔너리를 반환합니다.
>>> from chat.forms import PaikdabangMenuDocumentForm
>>> form = PaikdabangMenuDocumentForm(data={"page_content": x2})
>>> form.is_valid()
False
>>> form.errors
{'page_content': ['토큰 수는 최대 8191개여야 합니다 (현재 8192개).']}
PaikdabangMenuDocument 모델을 장고 관리자에 등록을 하셨다면,
관리자 페이지를 통해 장고 모델폼을 사용하실 수 있고, 유효성 검사 에러도 확인하실 수 있습니다.
chat/admin.py¶1from django.contrib import admin
2from .models import PaikdabangMenuDocument
3
4@admin.register(PaikdabangMenuDocument)
5class PaikdabangMenuDocumentAdmin(admin.ModelAdmin):
6 # form 인자를 지정하지 않으면, 내부에서 모델폼 클래스를 직접 생성하여 사용합니다.
7 # form = PaikdabangMenuDocumentForm
8 pass
http://localhost:8000/admin/ 페이지에 접속하시면 아래와 같이 PaikdabangMenuDocument 레코드 내역을 확인하실 수 있습니다.
슈퍼유저 계정 생성
슈퍼유저 계정이 생각나지 않으시면, uv run python manage.py createsuperuser 명령을 통해
새 슈퍼유저 계정을 생성하실 수 있습니다.
혹은 User 모델을 통해 슈퍼 유저를 조회하고 암호를 직접 변경하실 수도 있습니다.
# uv run python manage.py shell
>>> from django.contrib.auth import get_user_model
>>> User = get_user_model() # 현 프로젝트의 User 모델 클래스 조회
>>> user = User.objects.first() # 첫 번째 유저 조회
>>> user.set_password("원하는 암호") # 지정 암호를 해싱하여 .password 필드에 저장 (아직 데이터베이스 저장 전)
>>> user.save() # 데이터베이스에 User 인스턴스의 모든 모델 필드 저장
모델폼을 통해 입력폼도 자동으로 구성되구요. 새로운 PaikdabangMenuDocument 레코드를 생성할 때
8192개 토큰을 가지는 문자열을 지정하면 자동으로 유효성 검사가 수행되고 유효성 검사에 실패하고 유효성 검사 에러 메세지가 표시 됨을 확인하실 수 있습니다.
참 편리하죠? 😉
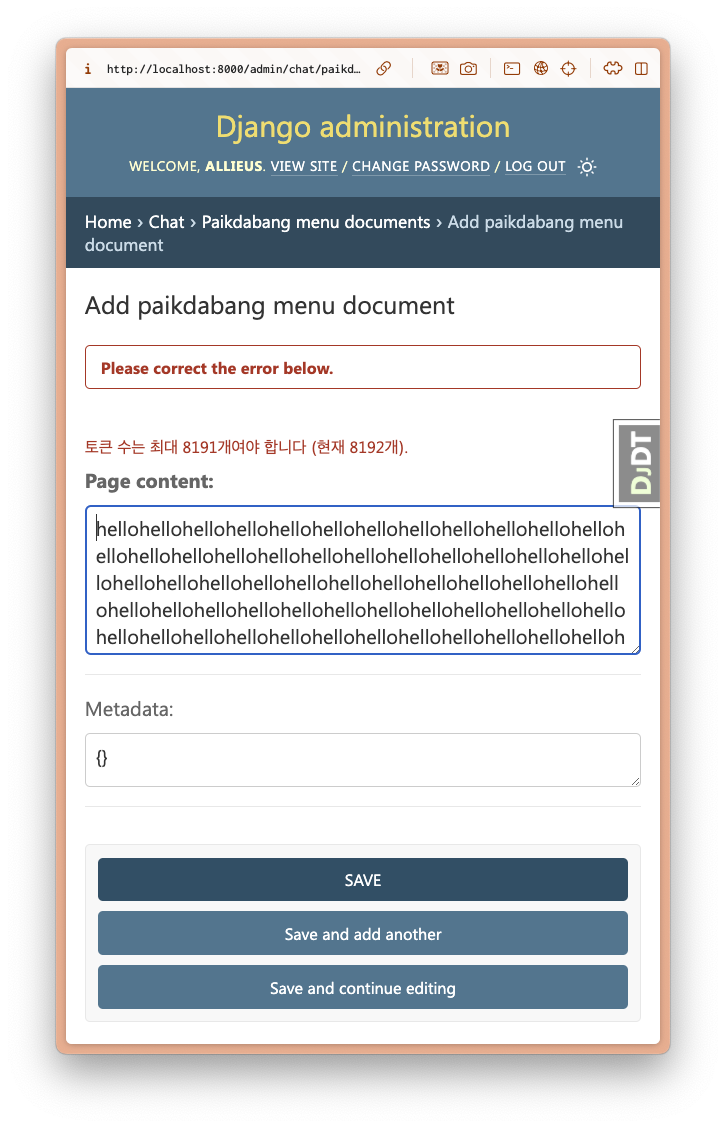
명령행에서 파이썬 코드 실행하기
8192개 토큰을 가지는 문자열은 아래 파이썬 코드로 손쉽게 클립보드에 복사해서 사용하실 수 있습니다. 클립보드에 복사하는 명령은 운영체제마다 다릅니다.
uv run python -c "print('hello' * 8192)" | Set-Clipboard
uv run python -c "print('hello' * 8192)" | clip
uv run python -c "print('hello' * 8192)" | pbcopy