3. 장고 모델에 pgvector 적용¶
pgvector 파이썬 라이브러리를 설치하고,
라이브러리에서 지원하는 모델 필드와 인덱스를 통해 유사도 검색을 구현해보겠습니다.
몸풀기로서 3차원 벡터를 저장하는 Item 모델을 통해 pgvector 확장과 장고의 통합을 체험해봅니다.
변경 파일을 한 번에 덮어쓰기 하실려면, pyhub-git-commit-apply 유틸리티 설치하신 후에, rag-02 폴더 상위 경로에서 아래 명령어 실행
uv run pyhub-git-commit-apply https://github.com/pyhub-kr/django-llm-chat-proj/commit/fbee535c6929b4f1966bf8efd07679577f875ee0
3.1. 라이브러리 설치¶
pgvector 라이브러리를 설치합니다.
공식문서에서 다양한 예시를 확인하실 수 있습니다.
장고,
SQLAlchemy 등을 지원합니다.
uv pip install --upgrade pgvector
3.2. 장고 모델 소개¶
장고 모델은 장고에서 지원하는 ORM (Object-Relational Mapping)이며, 장고의 핵심 기능입니다. 데이터베이스 테이블과 모델 클래스를 1:1로 매핑하여, 데이터베이스 테이블의 구조를 파이썬 클래스로 정의하구요. 장고 만의 간결한 문법으로 다양한 데이터베이스 작업을 수행할 수 있습니다.
데이터베이스마다 지원하는 SQL 문법이 다르지만, 장고 모델은 데이터베이스 종류에 상관없이
동일한 코드로 여러 데이터베이스에 걸쳐 데이터베이스 작업을 수행할 수 있습니다.
프로젝트 settings.DATABASES 설정만 변경해서, 그 즉시 다른 데이터베이스와 연동할 수 있습니다.
3.3. 장고 모델에 벡터 필드 추가하기¶
pgvector 라이브러리에서는 VectorField 모델 타입을 통해 벡터 데이터를 저장할 수 있습니다.
데이터베이스에는 vector(차원수) 타입으로 저장되며, 저장할 수 있는 벡터 데이터의 최대 차원 수는 2,000 입니다.
임베딩 벡터값을 저장할 모델에 VectorField 타입으로서 embedding 필드를 추가합니다.
dimensions 인자로 벡터의 차원 수를 지정하구요.
이 필드는 폼 필드로 입력을 받는 것이 아니라, 항상 코드를 통해 값을 할당할 것이기에 editable 인자로 모델 폼을 통한 편집을 원천적으로 막겠습니다.
chat/models.py¶from django.db import models
from pgvector.django import VectorField
class Item(models.Model):
embedding = VectorField(dimensions=3, editable=False)
참고
VectorField 타입은 vector 타입으로서 최대 2,000 차원까지 지원합니다.
이 외에도 HalfVectorField 타입은 halfvec 타입으로서 최대 4,000 차원까지 지원하며,
BitField 타입은 bit 타입으로서 최대 64,000 차원까지,
SparseVectorField 타입은 sparsevec 타입으로서 최대 1,000개의 0이 아닌 요소까지 지원합니다.
3.4. 벡터 필드에 인덱스 추가하기¶
pgvector 확장은 보다 빠른 벡터 검색을 위해 위해 2가지 인덱스 알고리즘을 지원합니다.
HnswIndex Hierarchical Navigable Small World 그래프 기반
다중 그래프를 생성하는 인덱스 방식
장점 : 빠른 속도와 높은 정확도
단점 : 느린 인덱스 생성, 높은 메모리 사용량
IvfflatIndex Inverted File with Flat Search 클러스터 기반
벡터들을 리스트로 나누고, 쿼리 벡터와 가장 가까운 리스트들의 부분집합을 검색하는 방식
HnswIndex대비 빠른 인덱스 생성과 적은 메모리 사용량이 장점이나, 검색 성능(속도/정확도는 트레이드오프)은 낮음
아래 예시에서는 정확도가 높은 HnswIndex 인덱스를 사용하겠습니다.
지식을 실시간으로 임베딩하는 것이 아니라 미리 임베딩된 벡터를 저장하는 것이므로,
인덱스 생성이 상대적으로 느려도 정확도가 높아진다면 무시할 수 있는 문제입니다.
chat/models.py¶ 1from django.db import models
2from pgvector.django import VectorField, HnswIndex
3
4class Item(models.Model):
5 embedding = VectorField(dimensions=3, editable=False)
6
7 class Meta:
8 indexes = [
9 # https://github.com/pgvector/pgvector?tab=readme-ov-file#index-options
10 HnswIndex(
11 name='item_embedding_hnsw_idx', # 유일한 이름이어야 합니다.
12 fields=['embedding'],
13 # 각 벡터를 연결할 최대 연결수
14 # 높을수록 인덱스 크기가 커지며 더 긴 구축시간, 더 정확한 결과
15 m=16, # default: 16
16 # 인덱스 구축시 고려할 후보 개수
17 ef_construction=64, # default: 64
18 # 인덱스 생성에 사용할 벡터 연산 클래스
19 opclasses=['vector_cosine_ops']
20 ),
21 ]
인덱스의 opclasses 인자에는 유사 문서 검색에 사용할 벡터 연산 클래스를 지정합니다.
pgvector 확장에서는 다음의 벡터 연산을 지원합니다.
이후 데이터베이스 조회 시에 사용할 벡터 연산을 지정해서 인덱스를 생성해야만, 인덱스를 통해 데이터베이스 조회가 이뤄집니다.
코사인 거리 연산 :
vector_cosine_ops,halfvec_cosine_opsL2 거리 연산 :
vector_l2_ops,halfvec_l2_opsL1 거리 연산 :
vector_l1_ops,halfvec_l1_ops내적 (inner product) 연산 :
vector_ip_ops,halfvec_ip_ops해밍 거리 연산 :
bit_hamming_ops자카드 거리 연산 :
bit_jaccard_ops
필드 |
인덱스 |
연산 |
설명 |
|---|---|---|---|
vector |
hnsw |
vector_cosine_ops |
코사인 거리 연산 |
vector_l2_ops |
L2 거리 연산 |
||
vector_l1_ops |
L1 거리 연산 |
||
vector_ip_ops |
내적 (inner product) 연산 |
||
vector |
ivfflat |
vector_cosine_ops |
코사인 거리 연산 |
vector_l2_ops |
L2 거리 연산 |
||
vector_ip_ops |
내적 (inner product) 연산 |
||
halfvec |
hnsw |
halfvec_cosine_ops |
코사인 거리 연산 |
halfvec_l2_ops |
L2 거리 연산 |
||
halfvec_l1_ops |
L1 거리 연산 |
||
halfvec_ip_ops |
내적 (inner product) 연산 |
||
halfvec |
ivfflat |
halfvec_cosine_ops |
코사인 거리 연산 |
halfvec_l2_ops |
L2 거리 연산 |
||
halfvec_ip_ops |
내적 (inner product) 연산 |
||
bit |
hnsw |
bit_hamming_ops |
해밍 거리 연산 |
bit_jaccard_ops |
자카드 거리 연산 |
||
bit |
ivfflat |
bit_hamming_ops |
해밍 거리 연산 |
필드 타입과 인덱스 타입에 따라 사용할 수 있는 벡터 연산이 다릅니다.
필드 타입과 인덱스 타입에 따라 사용할 수 있는 벡터 연산이 다릅니다. 타입에 맞지 않게 지정하시면 인덱스 생성에 실패합니다.
코사인 거리 연산을 사용할 경우
1536차원 벡터 필드를 저장할려면
VectorField타입을 쓰고,HnswIndex인덱스에vector_cosine_ops연산을 사용합니다.3072차원 벡터 필드를 저장할려면 2000차원을 넘기에
VectorField타입에는 담지 못하고HalfVectorField타입을 써야만 하고,HnswIndex인덱스를 사용하되,vector_cosine_ops연산을 사용할 수 없고halfvec_cosine_ops연산을 사용합니다.
3.5. 마이그레이션을 통해 데이터베이스에 반영하기¶
새로운 모델을 정의했으니, 이 모델 내역대로 데이터베이스 테이블을 생성하기 위해
makemigrations 명령으로 마이그레이션 파일을 생성해주세요.
$ uv run python manage.py makemigrations chat
Migrations for 'chat':
chat/migrations/0001_initial.py
+ Create model Item
chat/migrations/0001_initial.py 경로에 마이그레이션 파일을 생성만 했을 뿐,
아직 데이터베이스에는 미적용 상황입니다. 모델 수정이 필요한 상황이라면,
이 마이그레이션 파일은 아직 적용하지 않았기에 이 파일을 삭제하고 다시 생성하셔도 됩니다.
데이터베이스에 vector 확장이 활성화되어야만 vector 타입을 사용할 수 있는 데요.
chat/migrations/0001_initial.py 마이그레이션을 데이터베이스에 적용하기에 앞서,
데이터베이스에 vector 확장을 활성화하는 Operation을 추가하겠습니다.
마이그레이션을 수행하면, vector 확장부터 체크하고,
vector 타입이 지정된 테이블 생성을 시도하게 됩니다.
chat/migrations/0001_initial.py¶ 1# Generated by Django 5.1.5 on 2025-01-29 10:42
2
3import pgvector.django.indexes
4import pgvector.django.vector
5from pgvector.django import VectorExtension
6from django.db import migrations, models
7
8class Migration(migrations.Migration):
9 initial = True
10 dependencies = []
11
12 operations = [
13 VectorExtension(), # 먼저 수행되도록, 앞에 추가합니다.
14 migrations.CreateModel(
15 name="Item",
16 # ...
17 ),
18 ]
sqlmigrate 명령으로 특정 마이그레이션 파일을 수행했을 때, 실제 수행되는 SQL 쿼리를 확인할 수 있습니다.
-- uv run python manage.py sqlmigrate chat 0001_initial 명령
BEGIN;
--
-- Creates extension vector
--
-- (no-op)
--
-- Create model Item
--
CREATE TABLE "chat_item" (
"id" bigint NOT NULL PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
"embedding" vector(3) NOT NULL
);
CREATE INDEX "item_embedding_hnsw_idx" ON "chat_item"
USING hnsw (
"embedding" vector_cosine_ops
)
WITH (
m = 16,
ef_construction = 64
);
COMMIT;
마이그레이션의 VectorExtension() Operation 항목은 (no-op)로서 수행되는 쿼리가 현재 없는 것으로 보입니다.
앞서 [supabase] Postgre pgvector 설정하기 문서를 참고해서 데이터베이스를 생성하셨다면,
vector확장을 이미 활성화했으므로-- (no-op)로서 수행되는 쿼리가 없는 상황입니다.만약 [docker] Postgre pgvector 서버 구동하기 문서를 참고해서 데이터베이스를 생성하셨다면,
vector확장이 설치는 되어있지만 아직 활성화되어있지 않는 상황이므로,CREATE EXTENSION IF NOT EXISTS "vector";쿼리가 수행될 것입니다.
수행되는 SQL 내역을 확인했으므로 migrate 명령으로 실제 데이터베이스에 반영합니다.
$ uv run python manage.py migrate chat
[2025-01-29 11:03:50,777] Loaded vector store 10 items
Operations to perform:
Apply all migrations: chat
Running migrations:
Applying chat.0001_initial... OK
chat_item 테이블이 방금 생성되었구요.
supabase 서비스의 경우 Table Editor 페이지를 통해
생성된 테이블 내역을 확인하실 수 있습니다.
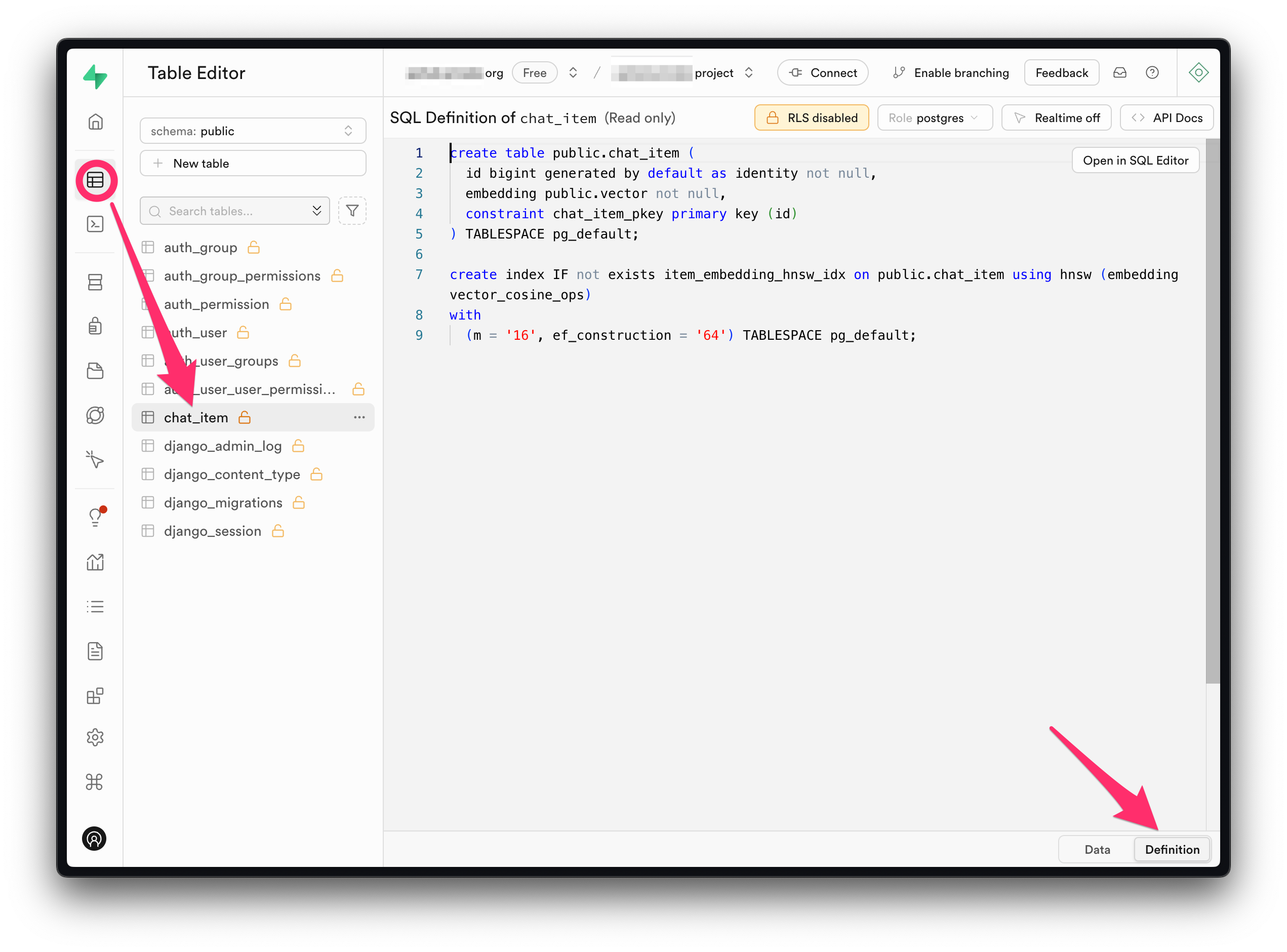
PyCharm Professional에서는 데이터베이스 툴이 지원되니, 툴에서 직접 데이터베이스에 접속해서 테이블 내역을 확인하실 수 있습니다.
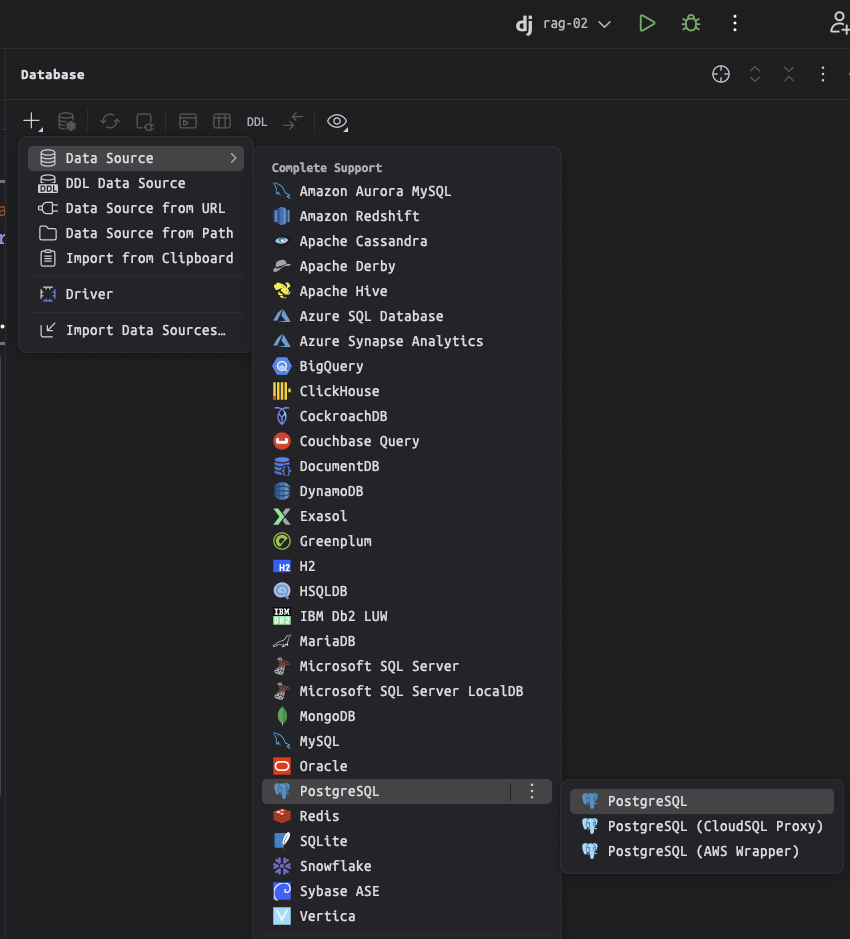
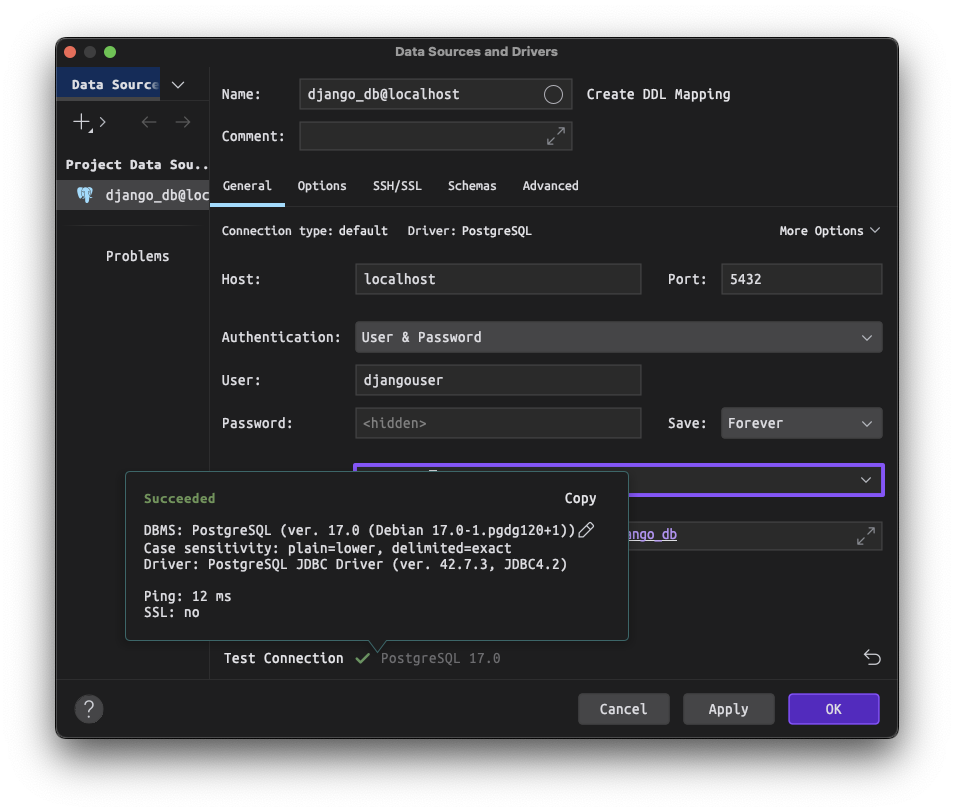
Visual Studio Code 기본에서는 데이터베이스 툴을 지원하지 않지만, PostgreSQL 확장을 통해 데이터베이스 툴을 사용할 수 있습니다.
확장 설치 후에, PostgreSQL Explorer 패널을 열고, + 버튼을 눌러서 데이터베이스 접속 정보를 입력합니다.
도커로 데이터베이스를 설치하신 경우,
호스트 주소는 127.0.0.1, 포트는 5432, 데이터베이스 유저명은 djangouser, 데이터베이스 이름은 djangopw,
포트번호는 5432, 보안연결 여부는 로컬일 경우 Standard Connection을 선택합니다.
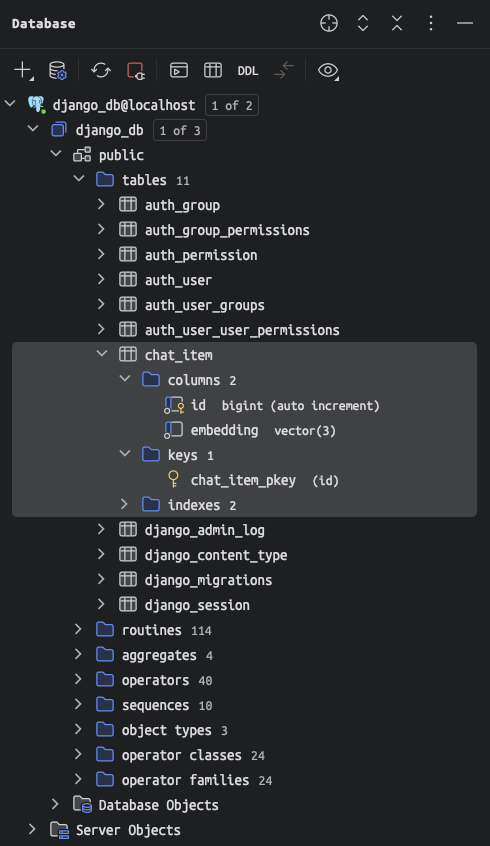
데이터베이스는 django_db를 선택하면 아래와 같이 데이터베이스에 연결되고 테이블 내역을 확인하실 수 있습니다.
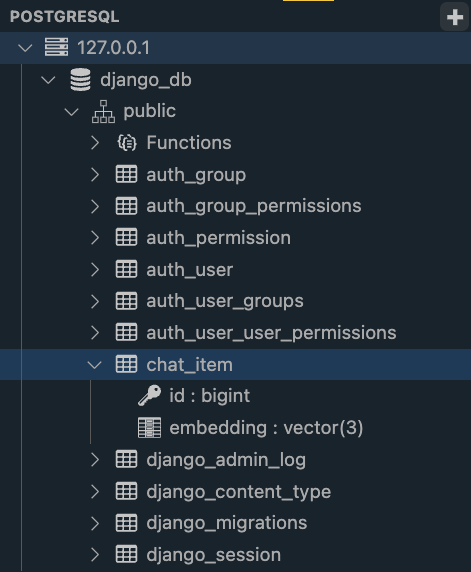
3.6. Item 레코드 생성하고, 수행 SQL 쿼리 확인하기¶
장고 쉘을 구동해서, Item 모델을 통해 벡터 데이터를 저장해보겠습니다.
수행되는 SQL 쿼리를 확인하기 위해 django-extensions 라이브러리의
shell_plus --print-sql 명령을 활용하겠습니다.
튜토리얼 프로젝트에는 이미 django-extensions 라이브러리가 설치되어있습니다.
팁
장고 쉘에서는 ipython 라이브러리가 설치되어있다면 ipython으로 쉘이 구동됩니다.
ipython 쉘이 사용성이 좋으므로 ipython 사용을 권장드립니다.
ipython 라이브러리 설치 후에 장고 쉘을 구동해주세요.
아래와 같이 장고 쉘을 구동하고, Item 모델을 통해 벡터 데이터를 저장하실 수 있습니다.
$ uv run python manage.py shell_plus --print-sql
>>> from chat.models import Item
>>> Item.objects.create(embedding=[1, 2, 3])
INSERT INTO "chat_item" ("embedding")
VALUES ('[1.0,2.0,3.0]') RETURNING "chat_item"."id"
Execution time: 0.015267s [Database: default]
<Item: Item object (1)>
경고
Item.objects.create(embedding=[1, 2, 3, 4])와 같이
임베딩 필드에 지정된 차원수(3)와 차원이 맞지 않는 데이터(4)를 지정하면
DataError: expected 3 dimensions, not 4와 같은 예외가 발생합니다.
다수의 Item 레코드를 생성하고,
for i in range(1, 4):
for j in range(1, 4):
for k in range(1, 4):
Item.objects.create(embedding=[i, j, k])
저장된 임베딩 데이터에 대해 코사인 거리 등 다양한 거리 계산을 수행할 수 있습니다.
CosineDistance, L2Distance, HammingDistance 등의
다양한 데이터베이스 함수가
지원됩니다.
Item모델에서embedding필드에 대해 코사인 거리 알고리즘으로 인덱스가 생성되어 있으므로, 인덱스 활용을 위해CosineDistance함수를 사용하겠습니다.코사인 거리가 작을수록 유사도가 높으므로 오름차순 정렬을 하고, 유사한 레코드를 4개 조회하겠습니다.
from pgvector.django import CosineDistance
qs = Item.objects.annotate(cosine_distance=CosineDistance('embedding', [3, 1, 2]))
# 코사인 거리는 유사도가 낮은 순서대로 정렬되어야 하므로 반드시 오름차순 정렬을 해야합니다.
qs = qs.order_by("cosine_distance")[:4]
print(qs.explain()) # 실행계획 출력
for item in qs:
print(item.pk, item.cosine_distance)
실행하면 다음과 같이 출력되구요.
pgvector를 통해 코사인 거리 (
<=>) 함수를 사용해서 유사한 레코드를 조회됨을 확인하실 수 있습니다.실행계획에서 전체 테이블을 스캔하지 않고, 인덱스를 통해 효율적으로 검색됨을 의미합니다. 모델에 정의된 인덱스와 다른 거리 함수를 사용하거나 내림차순 정렬을 했다면, 인덱스를 사용하지 못하고 전체 테이블을 스캔하게 됩니다.
EXPLAIN SELECT "chat_item"."id",
"chat_item"."embedding",
("chat_item"."embedding" <=> '[3.0,1.0,2.0]') AS "cosine_distance"
FROM "chat_item"
ORDER BY 3 ASC
LIMIT 4
Execution time: 0.016181s [Database: default]
Limit (cost=7.28..7.51 rows=4 width=48)
-> Index Scan using item_embedding_hnsw_idx on chat_item (cost=7.28..76.00 rows=1200 width=48)
Order By: (embedding <=> '[3,1,2]'::vector)
SELECT "chat_item"."id",
"chat_item"."embedding",
("chat_item"."embedding" <=> '[3.0,1.0,2.0]') AS "cosine_distance"
FROM "chat_item"
ORDER BY 3 ASC
LIMIT 4
Execution time: 0.018868s [Database: default]
22 0.0
12 0.0180194939380343
23 0.0189770568240547
13 0.0200421129877772