6. make_vector_store 명령 수정¶
변경 파일을 한 번에 덮어쓰기 하실려면, pyhub-git-commit-apply 유틸리티 설치하신 후에, rag-02 폴더 상위 경로에서 아래 명령어 실행
uv run pyhub-git-commit-apply https://github.com/pyhub-kr/django-llm-chat-proj/commit/bf9de8db17040a7301593f8e54bae3cfc6986b9e
6.1. PaikdabangMenuDocument 모델을 통한 저장 및 자동 임베딩¶
앞서 구현했던 make_vector_store 명령을 수정하여,
파이썬 리스트를 생성하고 pickle 포맷으로 저장하는 대신
PaikdabangMenuDocument 모델을 통해 저장토록 합니다.
진행 상황은 tqdm 라이브러리를 통해 표시하겠습니다. 라이브러리가 설치되어있지 않다면
uv run pip install --upgrade tqdm 명령으로 설치해주세요.
chat/management/commands/make_vector_store.py¶ 1from pathlib import Path
2
3# from django.conf import settings
4from django.core.management import BaseCommand
5from tqdm import tqdm
6
7from chat import rag
8from chat.models import PaikdabangMenuDocument
9
10
11class Command(BaseCommand):
12 def add_arguments(self, parser):
13 parser.add_argument(
14 "txt_file_path",
15 type=str,
16 help="VectorStore로 저장할 원본 텍스트 파일 경로",
17 )
18
19 def handle(self, *args, **options):
20 txt_file_path = Path(options["txt_file_path"])
21
22 doc_list = rag.load(txt_file_path)
23 print(f"loaded {len(doc_list)} documents")
24 doc_list = rag.split(doc_list)
25 print(f"split into {len(doc_list)} documents")
26
27 # vector_store = rag.VectorStore.make(doc_list)
28 # vector_store.save(settings.VECTOR_STORE_PATH)
29
30 # 문서 목록을 순회하며, 모델 인스턴스를 생성하고 저장합니다.
31 for doc in tqdm(doc_list):
32 paikdabang_menu_document = PaikdabangMenuDocument(
33 page_content=doc.page_content,
34 metadata=doc.metadata,
35 )
36 paikdabang_menu_document.save()
실행하면 다음과 같이 진행 상황이 표시되구요.
$ python manage.py make_vector_store ./chat/assets/빽다방.txt
[2025-01-29 14:40:09,940] Loaded vector store 10 items
loaded 1 documents
split into 10 documents
100%|███████████████████████████| 10/10 [00:06<00:00, 1.66it/s]
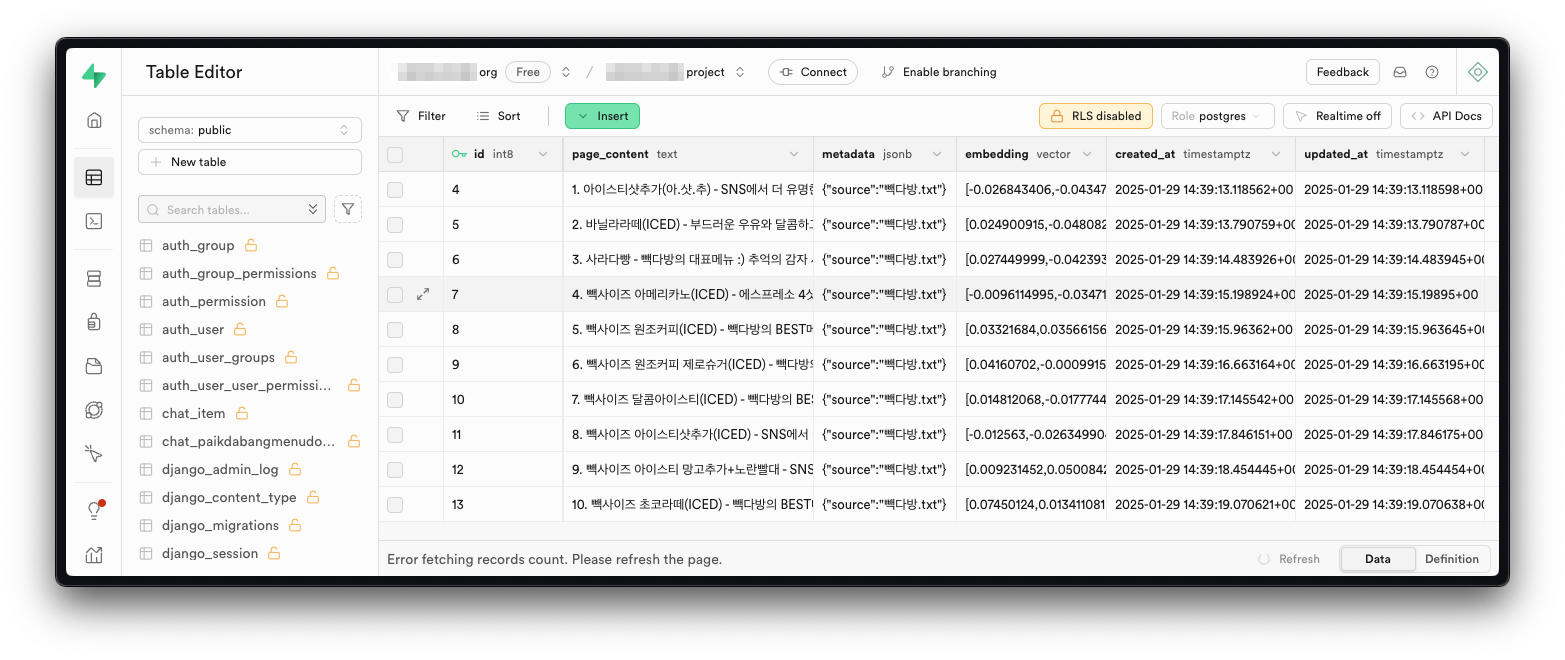
데이터베이스의 chat_paikdabangmenudocument 테이블을 조회하면, 임베딩 데이터가 자동으로 생성된 것을 확인하실 수 있습니다.
6.2. 개선 포인트¶
현재 코드는 각 PaikdabangMenuDocument 인스턴스마다 개별적으로 OpenAI Embedding API를 호출하고,
개별적으로 데이터베이스에 저장하고 있습니다. 이로 인해 다음과 같은 비효율이 발생합니다.
비효율적인 데이터베이스 삽입
각 문서마다 개별적으로 INSERT 쿼리를 실행하기보다, 여러 개의 INSERT 쿼리를 하나의 배치로 묶어 실행하면 트랜잭션 오버헤드를 줄이고 성능을 최적화할 수 있습니다.
API 호출 횟수 증가
각 문서마다 개별적으로 Embedding API를 호출하기에 네트워크 요청이 과도하게 발생합니다. 여러 개의 문서를 한 번의 API 요청으로 처리하면 전체 처리 시간을 단축할 수 있습니다.